
Il existe de nombreux blogs et programmes vidéo pour la vidéo sur la façon de préparer Filebeat et Logstash avec Elasticsearch auto-hosté. Mais quand j’ai essayé de connecter la même chose au nuage flexible, elle a rencontré de nombreux problèmes. En raison de la présence d’une petite discussion à ce sujet dans des forums communautaires tels que StockoveFlow ou leurs propres forums.
Tout d’abord, nous discuterons de la cause et de l’endroit où nous avons besoin de Filebeat et de Logstash. Ensuite, nous verrons comment nous pouvons connecter tout ce qui est à la fois dans Elasticsearch et Flexible Cloud.
Pourquoi avons-nous besoin à la fois de Filebeat et de Logstash?
Quand je préparais cela pour la première fois, j’étais très confus entre ces deux-là. J’avais l’impression de faire les mêmes choses: Les deux peuvent être lus à partir d’un fichier, convertir les enregistrements de la série JSON en JSON et ajouter des champs supplémentaires si nécessaire, etc. Mais après avoir utilisé chacun d’eux seuls et dans de nombreux projets, je me suis familiarisé avec les différences et j’ai commencé à les utiliser ensemble.
Comprenons cela en utilisant l’architecture:

Vous pouvez voir que nous utilisons Filebeat (ou tout autre rythme) sur le serveur principal où notre application ajoute des enregistrements au fichier de registre (fichiers). Le fichier FileBeat envoie des enregistrements au serveur Logstash qui est utilisé pour traiter / convertir des enregistrements et les envoyer à Elasticsearch.
Logstash peut être sur les mêmes serveurs ou différents. Mais je préfère généralement être sur un autre serviteur parce que:
- Pas léger comme Filebeat
- Nous pouvons gérer tous les pipelines pour traiter les enregistrements centraux sur un serveur.
La plus grande fonctionnalité du fichier filebeat est que même si le serveur Logstash a diminué, il continue de réévaluer. J’ai vu des enregistrements perdus dans le passé tout en utilisant Logstash seul. Bien sûr, Filebeat très léger.
En d’autres termes, j’utilise Filebeat pour lire les enregistrements du fichier (bien que Logstash puisse également le faire) et Logstash pour ajouter, supprimer ou modifier des données dans les enregistrements.
S’il n’est pas encore clair ou si vous voulez en savoir plus sur ce sujet, vous pouvez lire ceci.
Passons maintenant à la mise en œuvre.
Comment installer?
Même si vous utilisez un cloud flexible, vous devez installer Filebeat et vous connecter. Vous pouvez cependant utiliser des pipelines Logstash dans le nuage flexible. Nous en discuterons plus tard sur ce blog.
Accédez à la page de téléchargement et installez Elasticsearch, Kibana, Logstash et Filebeat (Beats) dans le même ordre. Il existe des instructions pour les installer à l’aide de fichiers ZIP; Des forfaits comme APT, Homebrew, miam, etc.; Ou docker. (Pour le cloud flexible, vous ne devez pas installer Elasticsearch et Kibana).
Préparation de la recherche élastique auto-hébergée
Après avoir installé avec succès ElasticSearch, exécutez ceci pour voir si c’est le cas:
curl localhost:9200Vous devez imprimer quelque chose comme ceci:
{
"name" : "ip-172-31-33-151",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "JPaSI3t1SK-qDXhkSapNmg",
"version" : {
"number" : "7.15.0",
"build_flavor" : "default",
"build_type" : "deb",
"build_hash" : "79d65f6e357953a5b3cbcc5e2c7c21073d89aa29",
"build_date" : "2021-09-16T03:05:29.143308416Z",
"build_snapshot" : false,
"lucene_version" : "8.9.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}Comprenons les formations de base:
Dans Ubuntu, les fichiers de configuration sont stockés dans /etc/elasticsearch guide. Vous pouvez vérifier où il est pour vos systèmes.
le elasticsearch.yml Le fichier dans ce guide est entièrement décrit par défaut, vous n’avez rien à changer pour un paramètre simple. Mais vous devrez peut-être modifier ces formations de production.
cluster.name: Pour définir le nom du groupe.node.name: Pour définir une description du nœud en cas de contrat multiple.path.data: Pour stocker les données. Vous voudrez peut-être changer cela sur le site souhaité.path.logs: Pour stocker les enregistrements. Si vous ne voulez pas perdre ces données, vous devez modifier le site.network.hostPar défaut, il ne peut être accessible quelocalhost. Vous devrez peut-être changer cela si vous l’installez sur un autre serveur.
Vous pouvez également explorer jvm.options Fichier si vous souhaitez former la taille de la pile JVM. Par défaut, il est automatiquement configuré par Elasticsearch basé sur la mémoire disponible dans votre système.
Préparé par Kibana
Après avoir suivi les étapes d’installation, si vous l’installez sur votre appareil local, vous pouvez vérifier le test d’installation en y accédant: localhost:5601 De votre navigateur.
Si vous installez ceci en utilisant un fournisseur de cloud comme AWS,
- Vous devez exposer le port
5601En utilisant des groupes de sécurité. - Aller à
/etc/kibanaGuide et ouvrirkibana.ymlPour modifier les configurations. embaucheserver.host: "0.0.0.0"Au lieu de “l’hôte local”. - Enfin, allez dans votre navigateur et atteignez cette
:5601
Jetons maintenant un œil aux configurations de base du fichier kibana.yml
-
server.hostLe titre que le serveur Kibana sera connecté. Il est hypothétique à un “hôte local” -
elasticsearch.hostsAdresses d’URL des homologues Elasticsearch pour une utilisation dans toutes vos demandes. -
Si Elasticsearch est protégé par la ratification de base, vous devez définir ceci:
elasticsearch.username&elasticsearch.password -
elasticsearch.serviceAccountToken: Pour ratifier Elasticsearch via “les” codes de calcul du service ” -
Pour activer SSL pour les demandes de Kibana Server au navigateur
-
server.ssl.enabled: Pour activer ou désactiver SSL. Les paramètres par défaut dans une erreur. -
server.ssl.certificate: Chemin vers votre fichier .crt -
server.ssl.key: Chemin vers votre fichier .key
-
Préparation de la connexion
Une fois que vous avez installé et responsabilisé la connexion, vous pouvez tester les configurations en suivant quelques exemples sur le site officiel. Si c’est la première fois ou luttez avec des filtres, retirez tout à l’intérieur du filtre et essayez de l’exécuter.
Comment tester les pipelines?
Vous pouvez trouver toutes les configurations dans /etc/logstash Répertoire (obonto). Si tu vois pipelines.yml Fichier, prend tous les fichiers à l’intérieur conf.d Le dossier se termine avec .conf. Vous pouvez également définir plusieurs pipelines avec plusieurs idS.
Si vous souhaitez simplement tester un fichier, vous pouvez exécuter ceci (pour Ubuntu):
/usr/share/logstash/bin/logstash -f filename.confCréons un pipeline de base pour Filebeat (pour l’auto-hosting)
input {
beats {
port => 5044
}
}
filter {
}
output {
elasticsearch {
hosts => ["localhost:9200"]
index => "applog-%{+YYYY.MM.dd}"
}
stdout { codec => rubydebug }
}- Ce pipeline écoutera le port 5044 pour toutes les entrées de rythmes tels que Filebeat.
- Les dossiers seront envoyés à la recherche locale élastique
- Il enverra des enregistrements à l’index à partir de
applog-Il se termine par l’histoire de ce disque particulier. (Par exempleapplog-2021-10-03)) - le
stdoutLa section nous aide en enregistrant tout sur la console.
Pipeline pour le nuage flexible:
input {
beats {
port => 5044
}
}
filter {
}
output {
elasticsearch {
cloud_id => "My_deployment:"
ssl => true
ilm_enabled => false
user => "elastic"
password => ""
index => "applog-%{+YYYY.MM.dd}"
}
stdout { codec => rubydebug }
} Ces configurations devraient bien fonctionner pour le cloud flexible.
Qu’en est-il de l’exploration des pipelines centraux de Flastic Cloud?
- Recherche et conquête
Logstash PipelinesSection à Kibana.
- Dans cette section, cliquez
Create pipeline.
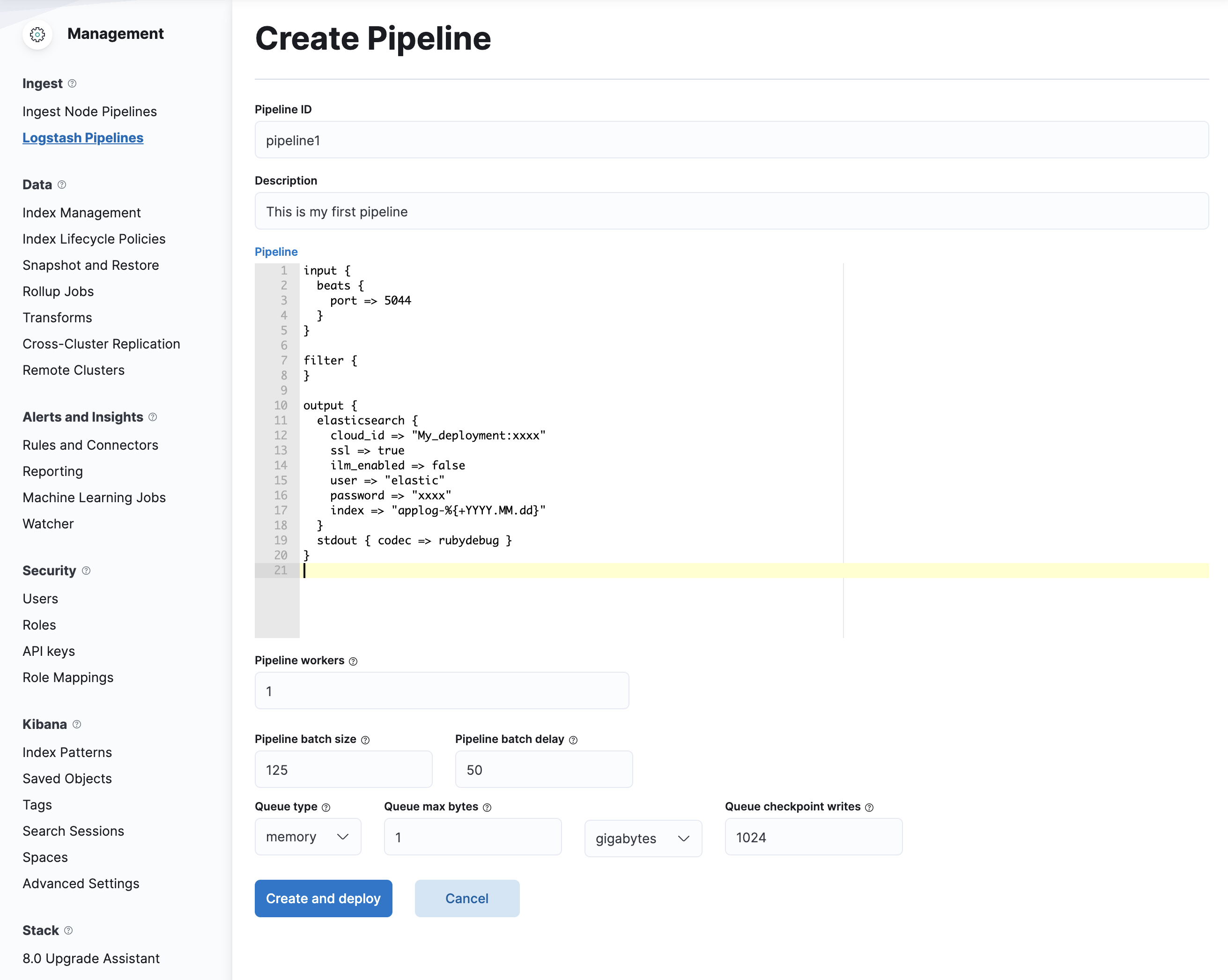
- À l’intérieur de la sélection de sipe, collez les détails ci-dessus et remplacez vos données de publication. Puis cliquez
Create and Deploy. Les formations devraient ressembler à ceci:
Maintenant, connectons Logstash à nos tubes
Note: Nous devons obtenir un homologue Logstash sur nos serveurs. Cela remplace simplement les pipelines et ne pas se connecter lui-même.
- Ouvrez votre
logstash.ymlDéposer/etc/logstashGuide Obonto. - Rechercher et ajuster ces configurations:
xpack.management.enabled: true
xpack.management.pipeline.id: ["pipeline1"] # ID of your pipeline
xpack.management.elasticsearch.cloud_id: management_cluster_id:xxxxxxxxxx
xpack.management.elasticsearch.cloud_auth: logstash_admin_user:passwordAprès avoir défini ces configurations, redémarrez votre service Logstash. Il contactera votre cloud et commencera à envoyer des enregistrements directement là-bas.
Par défaut, xpack.management.logstash.poll_interval Il a été nommé à 5s. Cela signifie qu’il y a des changements dans le pipeline toutes les 5 secondes.
PrepAAT filebeat
Passons rapidement à Filebeat maintenant.
Après l’installation, ouverte filebeat.yml Intérieur /etc/filebeat Pour ajuster les configurations.
Pour envoyer des enregistrements de base à Logstash, vous pouvez l’utiliser:
filebeat.inputs:
- input_type: log
enabled: true
paths:
- /var/log/elk.log
output.logstash:
hosts: ["127.0.0.1:5044"]- Ici, il écoute tout changement
/var/log/elk.logdéposer. - Les enregistrements sont envoyés au Logstash local, qui écoute déjà le port
5044.
Mais j’ai généralement mes enregistrements de candidature au format JSON. Vous pouvez les analyser à l’aide de Logstash, mais voyons comment vous pouvez le faire à l’aide de Filebeat.
filebeat.inputs:
- input_type: log
enabled: true
json.keys_under_root: true
paths:
- /var/log/elk.log
fileds_under_root: true
output.logstash:
hosts: ["127.0.0.1:5044"]
processors:
- decode_json_fields:
fields: ["something"]
process_array: true
overwrite_keys: true
add_error_key: trueAprès avoir modifié ce fichier, redémarrez Filebeat. Si tout est préparé correctement, cela devrait bien fonctionner.
Vous pouvez démarrer le test en inscrivant des enregistrements JSON à /var/log/elk.log déposer.
echo '{"hello": "world"}' >> /var/log/elk.logDisons après un certain temps, vous voudrez peut-être ajouter, modifier ou supprimer certains champs. Vous pouvez le faire directement via le pipeline Logstash.
Par exemple, cette modification peut vous aider à ajouter un nouveau champ à vos enregistrements JSON. Vous pouvez rechercher tous les filtres Logstash et l’utiliser en conséquence.
filter {
mutate {
add_field => { "new" => "key" }
}
}Imaginons ceci sur Kibana
Assurez-vous que les données sont poussées sur Elasticsearch.
- Rechercher
Index Patterns.
- Faire un clic
Create index pattern. Vous verrez quelque chose comme ceci:
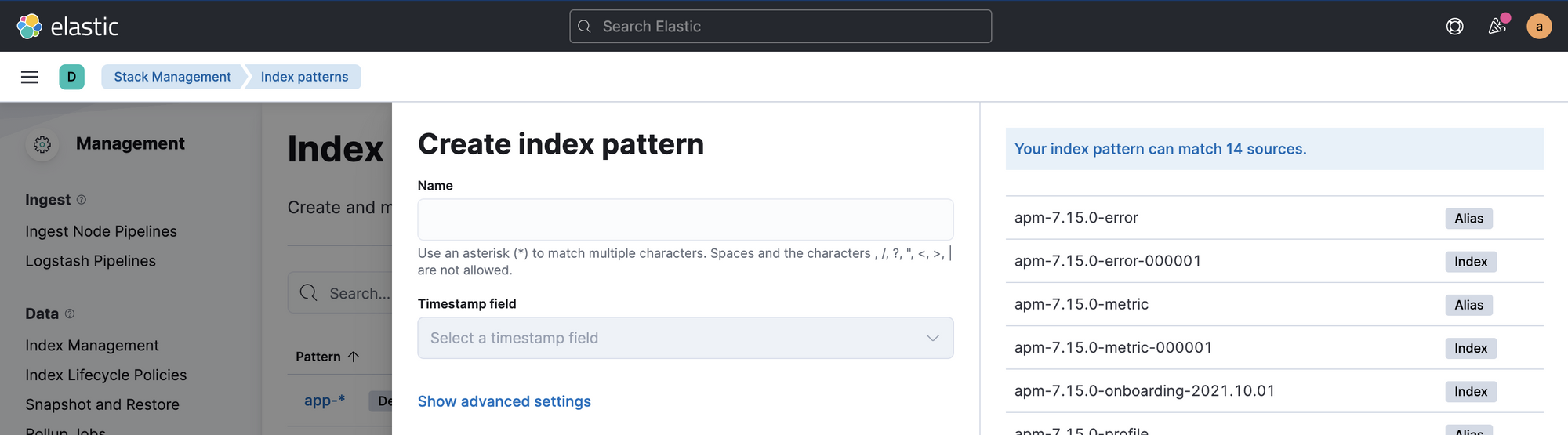
- dans
NameLe champ, entrezapplog-*Vous verrez l’index nouvellement créé pour vos enregistrements. Il choisit@timestampàTimestamp fieldFaire un clicCreate index pattern. - Aller maintenant
DiscoverLa section (vous pouvez également rechercher cela si vous ne savez pas comment le faire) et sélectionner votre style d’index. Vous pourrez voir les enregistrements. De plus, si vous avez payé les dossiers à un moment donné et que vous n’apparaissez pas, essayez de modifier la plage de temps.
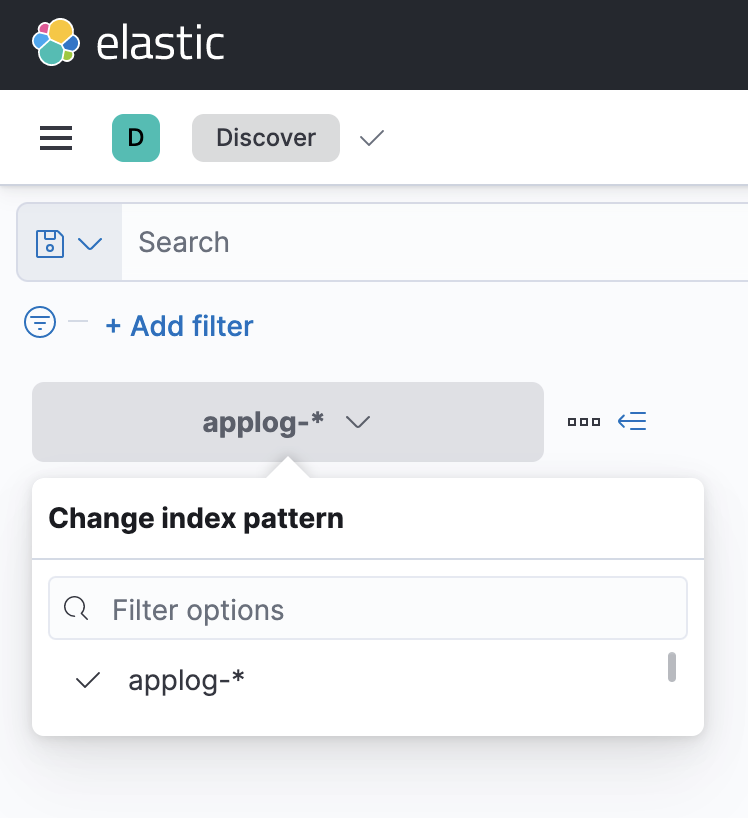
conclusion
J’utilise donc cette composition pour les projets:
Logs inside a file -> Filebeat -> Logstash -> ElasticSearchVous pouvez ajuster / supprimer les ingrédients en fonction de vos besoins. Si vous aimez ces blogs, veuillez vous abonner ci-dessous. Tu peux aussi me suivre gazouillement.